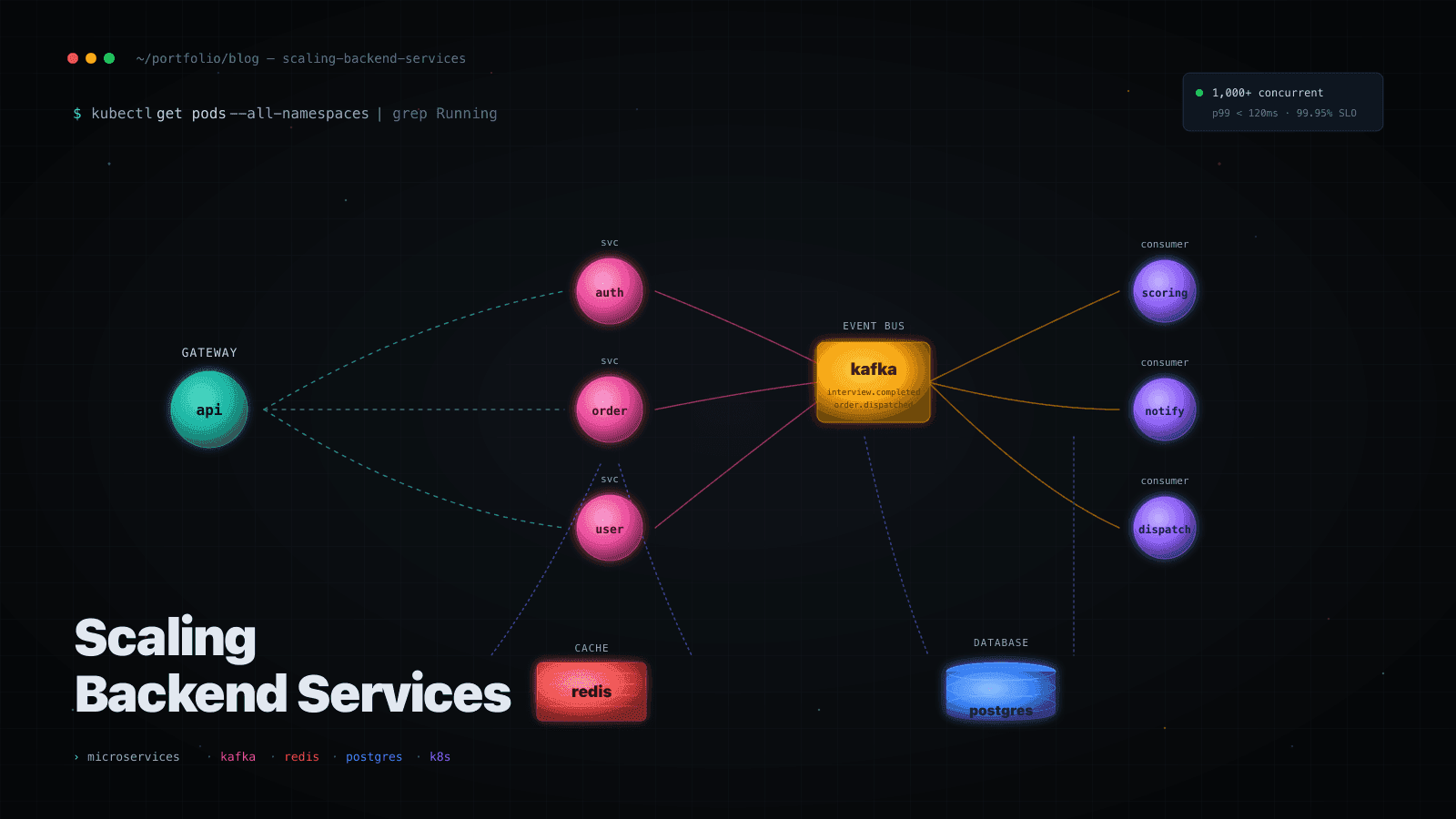
Context
Between MokaHR and Tongcheng Travel, I spent several years working on backend systems that couldn't afford downtime — an enterprise HR SaaS serving thousands of companies, and a ride-hailing platform processing real-time orders under sustained load. These are the lessons that stuck.
Microservices Are a Governance Problem, Not a Technical One
At MokaHR, we migrated a Node.js monolith to a Java Spring Cloud microservices architecture. The hardest part wasn't the migration itself — it was defining service boundaries. Services that are too fine-grained create a distributed monolith: all the operational complexity of microservices with none of the independence.
The rule I came back to: a service should own its data store and be deployable without coordinating with another team. If two services always deploy together, they're one service.
Kafka for Async Decoupling, Not Just Throughput
We introduced Kafka at MokaHR primarily to decouple interview-related event processing — resume parsing, scoring, notifications — from the synchronous request path. The throughput benefit was secondary.
The pattern that worked: write operations that don't need to be synchronous get published as events. Consumers process them independently and can be scaled or redeployed without touching the producer.
// Producer — fire and move on
kafkaTemplate.send("interview.completed", InterviewEvent.of(interviewId, result));
// Consumer — processes independently, retries on failure
@KafkaListener(topics = "interview.completed", groupId = "scoring-service")
public void onInterviewCompleted(InterviewEvent event) {
scoringService.evaluate(event.getInterviewId());
}
The gotcha: Kafka guarantees at-least-once delivery. Your consumers need to be idempotent. We used a processed_event_ids table with a unique constraint as the simplest idempotency check.
Redis Is Not Just a Cache
Redis does caching, but at Tongcheng we also used it for distributed locks (order deduplication), sorted sets (driver dispatch queues), and pub/sub (real-time dispatch notifications). Understanding its data structures unlocks a lot.
For the ride-hailing dispatch queue, available drivers were stored in a Redis sorted set keyed by proximity score. Finding the nearest available driver became an ZRANGEBYSCORE call — sub-millisecond at scale.
// Add driver to dispatch pool
redisTemplate.opsForZSet().add("dispatch:available", driverId, proximityScore);
// Pop the closest available driver (atomically via Lua script)
List<Object> result = redisTemplate.execute(dispatchScript, keys, args);
The Database Is Almost Always the Bottleneck
This held true across every system I worked on. The three patterns that cause the most pain:
-
Missing indexes on join columns and filter predicates. A
EXPLAIN ANALYZEin PostgreSQL orEXPLAINin MySQL takes 30 seconds and immediately shows you a full table scan. -
N+1 queries inside loops. Fetching a list of 200 candidates and then querying each one's interview history individually inside a loop kills performance. Batch the secondary queries or use a join.
-
Lock contention on hot rows. In order systems, the row representing an order's current state gets written to frequently. Long transactions holding row locks block everything else. Keep transactions short; update status fields in a separate lightweight write.
Observability Has to Ship with the Feature
At MokaHR, we adopted structured JSON logging with trace IDs early. When a support ticket arrived about a failed interview session, we could correlate the user's action across five services using a single trace ID. Without it, debugging distributed failures is archaeology.
The minimum viable observability stack for a Java Spring Cloud service:
- SLF4J + Logback with JSON layout and MDC for trace propagation
- Micrometer + Prometheus for request rate, latency percentiles, error rate
- Spring Cloud Sleuth (or OpenTelemetry) for distributed tracing
Ship these on day one, not after the first production incident.
Horizontal Scaling Requires Stateless Services
Kubernetes made horizontal scaling easy at the infrastructure level. The hard part is ensuring services don't hold local state. Any session data, in-flight request context, or cache that lives in JVM memory breaks when the instance is replaced.
The checklist: no in-memory session, no local file writes, no JVM-level caches that aren't backed by Redis. If a service can be killed and restarted without a user noticing, it's ready to scale horizontally.